
Methodische Anmerkungen
Die Ergebnisse des Projekts “Wer kann mitmachen?” basieren auf einer repräsentativen Umfrage von Menschen mit und ohne Migrationsbiografie im Alter zwischen 16 und 74 Jahren in Deutschland. Die Umfrage wurde vom 7. bis 22. Mai 2021 erhoben. Sie wurde online durchgeführt durch das Umfrageinstitut Bilendi, die in Deutschland ein Panel mit über 250,000 Teilnehmenden haben, im Auftrag von d|part. Dabei wurden zwei Stichproben erstellt:
- Menschen ohne einen statistischen Migrationshintergrund (N=1003)
- Menschen mit einem statistischen Migrationshintergrund (N=2009)
Als Mensch mit einem statistischen Migrationshintergrund wurden Personen identifiziert, die entweder selber nicht in Deutschland geboren wurden, von denen ein Elternteil nicht in Deutschland geboren wurde oder von denen entweder die Großeltern mütterlicher oder väterlicherseits im Ausland geboren wurden.
Ziel war es, für beide Gruppen Stichproben zu entwickeln, die den jeweiligen Teil der Gesamtbevölkerung so nah wie möglich repräsentiert. Dazu wurde ein detailliertes Quoten-Design erstellt, um bei der Erhebung sicherzustellen, dass sich die jeweiligen Stichproben in der Zusammensetzung anhand verschiedener Merkmale der Bevölkerung stark ähneln. Das Quotendesign wurde dabei differenziert für beide Sitchproben (also jeweils für Menschen mit einem und ohne statistischen Migrationshintergrund) erstellt. Grundlage waren Daten des statistischen Bundesamts. Dabei wurde die Verteilung für beide Stichprobengruppen durch Quoten nach folgenden Characteristika abgebildet:
- Alter (je für Menschen mit einem und ohne einen statistischen Migrationshintergrund),
- Geschlecht (je für Menschen mit einem und ohne einen statistischen Migrationshintergrund),
- Bildungsstand (je für Menschen mit einem und ohne einen statistischen Migrationshintergrund),
- Berufssituation (je für Menschen mit einem und ohne einen statistischen Migrationshintergrund),
- Bundesland (je für Menschen mit einem und ohne einen statistischen Migrationshintergrund).
Um zusätzlich sicherzustellen, dass die Verteilung sowohl demographischer als auch sozio-ökonomischer Faktoren innerhalb verschiedener Gruppen die Bevölkerung insgesamt korrekt widerspiegelt, wurden zusätzlich Kreuzquoten erstellt, die bei der Rekrutierung eingesetzt wurden. Diese Kreuzquoten waren:
- Geschlecht X Alter (dadurch wurde die Geschlechterverteilung innerhalb jeder Altersgruppe der Bevölkerung entsprechend abgebildet),
- Bildung X Bundesland (dadurch wurde die Bildungsverteilung innerhalb jedes Bundeslandes der Bevölkerung entsprechend abgebildet),
- Beruf X Alter (dadurch wurde die Berufsverteilung innerhalb jeder Altersgruppe der Bevölkerung entsprechend abgebildet).
Um die Umfrage auch für Menschen zugänglich zu machen, die eine andere Sprache als Deutsch besser sprechen und deswegen eher dazu neigen könnten, teilzunehmen, wenn sie die Umfrage in ihrer Hauptsprache beantworten könnten, konnten Teilnehmende zu Beginn zwischen mehreren Sprachoptionen auswählen. Die Umfrage wurde dazu im Vorfeld von Expert:innen ins Türkische, Russische und Arabische übersetzt. Die programmierten Umfragen wurden von diesen Expert:innen auch noch einmal überprüft, um die korrekte Implementierung der Übersetzungen in der Umfragedurchführung sicherzustellen. 69 Personen (3,4% der Menschen mit einem statistischen Migrationshintergrund) machten von der Möglichkeit Gebrauch, die Umfrage in einer anderen Sprache zu beantworten (31 auf Arabisch, 19 auf Türkisch und 19 auf Russisch).
Das Projektteam hat ebenfalls externe Unterstützung zur Fragebogenentwicklung ersucht. Dazu wurde ein Expert:innenscoping mit Akteur:innen aus Wissenschaft, Zivilgesellschaft, Politik und Medien zu dem Thema durchgeführt. Dabei wurde neben dem methodischen Studiendesign vor allem besprochen, wie mit komplexen Konzepten (wie Rassismuserfahrungen, Diskriminierung und Identität) sowie Kernbegriffen (wie Migrationshintergrund) umgegangen werden sollte. Außerdem wurde besprochen, welche Erkenntnisse aus bestehenden Studien als gegeben angesehen werden konnten und bei welchen Fragestellungen Wissenslücken bestehen.
Nach einem Soft-Launch mit 50 Teilnehmenden zur Überprüfung der Programmierung in der Praxis am 7. Mai 2021 begann die Hauptfeldarbeit. Die Datenerhebung wurde langsam vorgehend durchgeführt, um sicherstellen zu können, dass sich die Profile der Teilnehmenden über alle Quotengruppen ausbalanciert verteilen und gegebenenfalls verstärkt Gruppen eingeladen werden konnten, die beispielsweise zu einem bestimmten Zeitpunkt weniger häufig als andere die Teilnahmeeinladung angenommen hatten.
Die Vorgehensweise war sehr erfolgreich, da Abweichungen von den angepeilten Bevölkerungsquoten erst spät in der Datenerhebung erlaubt werden mussten. Eine Kreuzquotenkombination (höchste Altersgruppe X Beruf) wurde gelockert als bereits ungefähr 90% der Menschen ohne einen und 70% der Menschen mit einem statistischen Migrationshintergrund teilgenommen hatten. Weitere Kreuzquoten wurden gelockert, als die Rekrutierung von Menschen ohne einen und mit einem statistischen Migrationshintergrund jeweils bei über 97% und 94% lag. Hauptquoten mussten nur für bei der Rekrutierung innerhalb der letzten 2% der Stichprobe gelockert werden.
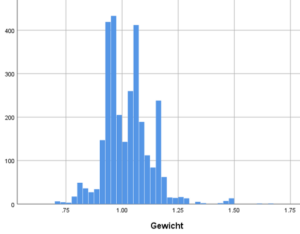
Abweichungen in den fünf oben genannten Bevölkerungscharakteristika, die zur Quotierung benutzt wurden, sind anschließend durch Gewichte korrigiert worden. Da die Datenerhebung aber sehr nah am Quotendesign lag, blieben die Gewichte insgesamt jedoch gering. Wie das Histogram zeigt, haben nur wenige Fälle ein Gewicht, dass größer ist als 1,2 oder kleiner als 0,83 (je circa 3%). Der Einfluss der Gewichte auf die Analysen ist dementsprechend sehr gering. Deskriptive Ergebnisse in den Analysen im Projekt werden durch die Nutzung der Gewichte durchgängig um weniger als 2‑Prozentpunkte beeinflusst. In den im Bericht präsentierten Analysen werden die Gewichte durchgängig angewendet.
Für weitere Rückfragen zur Methodik steht das Projektteam jederzeit gern zur Verfügung.